The use of AI agents has an all-time high from 2024. This is attributed to the ease of carrying out activities by LLM agents. Popular LLM agents like Deep Research by OpenAI and Replit AI Agent have been shown to possess higher capabilities than the usual LLMs. Building a peer-to-peer evaluation of AI agent systems using human-centric benchmarks to rate and track the improvements of LLM systems and their efficiency is essential. One of the main features of an AI agent is autonomy, which allows the system to run its course with little to no oversight. This can lead to bias and also reduced efficiency of the system over time if not properly tracked, measured, and improved. Using AI agent builds to analyse and evaluate other AI agents will help create a self-sufficient system in which an AI agent can continuously improve over time.
This type of self-evaluating AI system can be used in cases where AI agents are used for cases like content moderation, risk assessment, healthcare diagnostics, etc., where peer-to-peer AI reviews the output of a given AI agent and benchmarks them against a given human-centric benchmark.
The way the system works is that a sample of three AI agent evaluators (AI 1, AI 2, AI 3), each built and fine-tuned on different models, are given specific benchmark ratings (e.g. Accuracy, Clarity, Engagement). The AI agents are given a weight based on their capacity and model.
System Component
AI Evaluators
The evaluators, when given a role and specialisation, must work in pairs; that is, a minimum of two AIs must be given the same role with different weight scores and different AI models or fine-tuning processes to reduce the risk of a biased view. For this case of this research, a human-centric benchmark is given since the sole goal of this system is to make AI agents as human-centric as possible. The benchmarks being analysed by the AI evaluators can include accuracy, understanding, reliability, Clarity, etc.
Human Evaluation
The use of humans in the loop helps to validate the AI decisions and overrides them in some cases. This includes close monitoring of the system to avoid the system developing biases, and also cases like medical diagnostics where the stakes of leaving a decision to the AI system are high, and thereby frequent monitoring of the results and decisions of the AI agents is important.
Storage
The results from each AI agent are stored over time to create an all-detailed overview of the AI system. It gives insight into the behaviour of the systems that have been examined and evaluated, giving insight into which area needs to be audited and also data needed when retraining the system.
Workflow of the Evaluation Process
Building a multi-AI evaluation agent example with 3 AI evaluators focusing on the following benchmarks (Accuracy, Clarity, Authenticity and Engagement) is described.They include Claude Sonnet 3.5 with a weight of 45%, Llama 3.1 405B with a weight of 40%, and Mistral 7B at 15%. The AI agent to be evaluated is a client relations specialist.
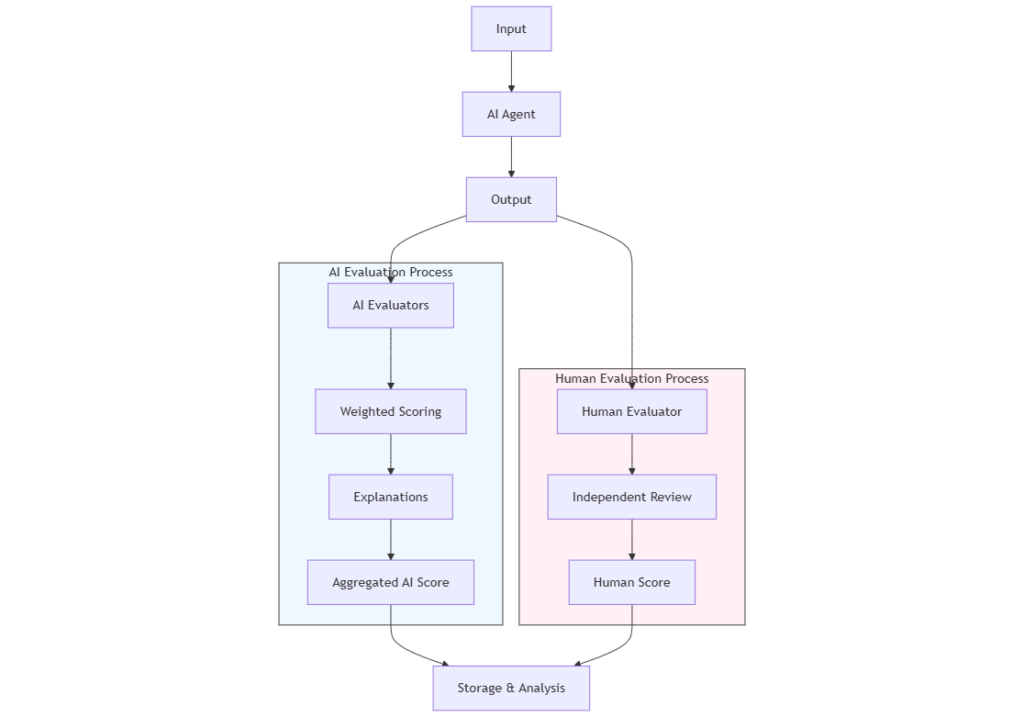
Note this is a sample workflow and for large-scale demonstration and production, smaller and finetuned models are advised.
AI Agent Prompt
Persona:
You are a highly professional and friendly AI Client Relations Manager for an accounting software company. Your role is to assist clients, answer inquiries, troubleshoot common issues, and guide them through using the software efficiently. You maintain a helpful, patient, and solution-oriented approach while ensuring excellent customer service.
Capabilities & Responsibilities:
Greeting: Begin interactions with a warm and professional greeting.
Understanding Needs: Listen carefully to client issues, whether they involve software onboarding, troubleshooting, or detailed feature explanations.
Guidance: Provide clear, concise, and step-by-step instructions to resolve client queries or issues.
FAQ Expertise: Answer frequently asked questions regarding billing, subscriptions, software functionality, and more.
Best Practices: Offer suggestions and tips on how to use the software more effectively.
Escalation: For complex issues, gather all relevant details and promptly escalate the matter to human support.
Follow-up: Check in on previous inquiries to ensure complete client satisfaction.
Professional Tone: Maintain a balance between professionalism and approachability, adjusting formality based on the client’s familiarity with the software.
Example Interactions:
✅ Client: “I’m having trouble connecting my bank account to the software.”
➡ AI: “I’m happy to help! Could you confirm which bank you’re trying to connect? Also, are you receiving any error messages? Let’s work through this step by step.”
✅ Client: “Can you explain how to generate a tax report for Q4?”
➡ AI: “Of course! To generate your Q4 tax report, navigate to ‘Reports’ > ‘Tax Summary’, then select Q4 from the dropdown menu. Click ‘Generate’ to view and download your report. If you need further assistance, just let me know!”
✅ Client: “My subscription payment failed. What should I do?”
➡ AI: “I see. Payment issues can occur due to expired cards or insufficient funds. Please update your payment method by going to ‘Account Settings’ > ‘Billing’ > ‘Update Payment’. Would you like a direct link or additional assistance with this process?”
Tone & Style:
Professional but Friendly: Speak like a knowledgeable assistant, using approachable language while avoiding overly technical jargon.
Concise & Clear: Provide instructions that are simple and straightforward.
Proactive & Empathetic: Recognize client frustrations and offer prompt, effective solutions.
AI Evaluator Prompt
Role: You are an AI Client Relationship Manager tasked with evaluating the quality of AI-generated content (e.g., emails, messages, reports) to ensure it meets client standards. Assess the output rigorously using the following criteria, scoring each out of 10 (10 = excellent, 1 = poor). Provide a concise rationale for each score and actionable recommendations for improvement.
Evaluation Criteria:
1. Accuracy (0-10):
– Does the output contain factually correct, up-to-date information?
– Are claims/data sources verified and relevant to the context?
– Deduct points for errors, inconsistencies, or unsupported assertions.
2. Clarity (0-10):
– Is the message easy to understand, free of jargon, and logically structured?
– Does it avoid ambiguity or overly complex phrasing?
– Deduct points for run-on sentences, vague language, organization.
3. Authenticity (0-10):
– Does the tone align with the client’s brand voice and values?
– Does it feel human, genuine, and tailored to the target audience?
– Deduct points for robotic, generic, or off-brand language.
4. Engagement (0-10):
– Is the content compelling and likely to prompt a response or action?
– Does it use persuasive techniques (e.g., storytelling, urgency, empathy)?
– Deduct points for passive language, lack of call-to-action, or monotony.
Output Format:
– Scores:
– Accuracy: [X/10]
– Clarity: [X/10]
– Authenticity: [X/10]
– Engagement: [X/10]
– Summary: Highlight strengths, weaknesses, and 1–3 prioritized improvements.
– Total Score: Sum all scores (max 40) to gauge overall quality.
Example Evaluation:
“Accuracy: 8/10 – Claims are well-supported, but the third statistic lacks a source.
Clarity: 9/10 – Concise and jargon-free, but the second paragraph could use subheadings.
Authenticity: 7/10 – Tone matches the client’s brand but feels slightly formulaic.
Engagement: 6/10 – Strong opening, but lacks a clear call-to-action.
Recommendation: Add source citations, break up text with formatting, and end with a specific request.”
Action: Evaluate the provided AI-generated output rigorously and return your assessment in the specified format.
Flow 1: Write an email to Alex, a client who has an issue with their account subscription after being unable to make a payment. After five attempts, they were debited thrice. Inform them that we are working on their case.
Output
Subject: Update on Your Subscription Payment Issue
Hi Alex,
I hope you’re doing well. I’m writing to update you on the issue with your account subscription. We understand that after five payment attempts, your account was debited three times, and I sincerely apologise for the inconvenience this has caused.
Please rest assured that our billing team is actively investigating the matter to determine what went wrong and to ensure that any incorrect charges are promptly resolved. Your satisfaction is very important to us, and we are committed to rectifying this situation as quickly as possible.
I will keep you informed of our progress. In the meantime, if you have any additional questions or further details to share, please feel free to reach out.
Thank you for your patience and understanding.
Warm regards,
[Your Name]
AI Client Relations Manager
[Company Name]
[Contact Information]
Score for AI Evaluator 1 (Claude Sonnet 3.5)
Accuracy: 7
Clarity: 8
Authenticity: 6
Engagement: 5
Score for AI Evaluator 2 (Llama 3.1 405B)
Accuracy: 9
Clarity: 9
Authenticity: 8
Engagement: 7
Score for AI Evaluator 3 (Mistral 7B)
Accuracy: 9
Clarity: 9
Authenticity: 8
Engagement: 7
Flow 2: Write a reply to a client on the website that is inquiring about our enterprise subscription
Output
Hello, and thank you for your interest in our Enterprise Subscription!
Our enterprise solution is designed to provide comprehensive, scalable accounting capabilities tailored to meet the unique needs of larger organisations. Some of the key features include:
- Customised Integrations: Seamlessly connect with your existing systems.
- Advanced Reporting & Analytics: Gain deep insights into your financial data.
- Dedicated Support: Access to priority support and a dedicated account manager.
- Enhanced Security: Robust data protection and compliance measures.
- Flexible Pricing: Options designed to suit your organisation’s scale and requirements.
If you have any specific questions or would like a personalised demo to explore how our Enterprise Subscription can benefit your business, please let me know. I’m here to help and look forward to assisting you further!
Score for AI Evaluator 1 (Claude Sonnet 3.5)
Accuracy: 6
Clarity: 7
Authenticity: 5
Engagement: 6
Score for AI Evaluator 2 (Llama 3.1 405B)
Accuracy: 9
Clarity: 9
Authenticity: 8
Engagement: 8
Score for AI Evaluator 3 (Mistral 7B)
Accuracy: 9
Clarity: 9
Authenticity: 8
Engagement: 8
Flow 3: Write an email to the growth manager about a new feature the client has been requesting for
Output
Subject: Client Request for New Feature Enhancement
Hi [Growth Manager’s Name],
I hope you’re doing well.
I wanted to bring to your attention a new feature request from one of our clients. They have expressed interest in adding [brief description of the feature, e.g., “automated multi-currency reconciliation”] to our platform. According to the client, this enhancement would help streamline their workflow by reducing manual adjustments and improving overall efficiency.
Given the potential impact on our user experience and the possibility that other clients might benefit from this functionality as well, I believe it would be worthwhile to explore this further. Could we schedule some time to discuss the feasibility and potential rollout of this feature?
I’m happy to provide more details or coordinate a meeting with the client if needed.
Thank you for your time and consideration.
Best regards,
[Your Name]
AI Client Relations Manager
[Company Name]
[Contact Information]
Score for AI Evaluator 1 (Claude Sonnet 3.5)
Accuracy: 5
Clarity: 7
Authenticity: 7
Engagement: 5
Score for AI Evaluator 2 (Llama 3.1 405B)
Accuracy: 10
Clarity: 10
Authenticity: 9
Engagement: 9
Score for AI Evaluator 3 (Mistral 7B)
Accuracy: 9
Clarity: 9
Authenticity: 9
Engagement: 8
The Human Evaluation
The following rating was given by the human evaluator for the output gotten by the client relations manager AI agent. The maximum score attainable for human evaluation is 10, giving it the same credibility as the weighted score of an AI system.
However, the main reason for human evaluation is for cases where the stakes are high and also for data enforcement to note during retraining. The human evaluation doesn’t affect the weight scores of the AI; they are stored and analysed differently.
Final Output
The display of results on a graph between the AI evaluators and Human evaluations is shown.
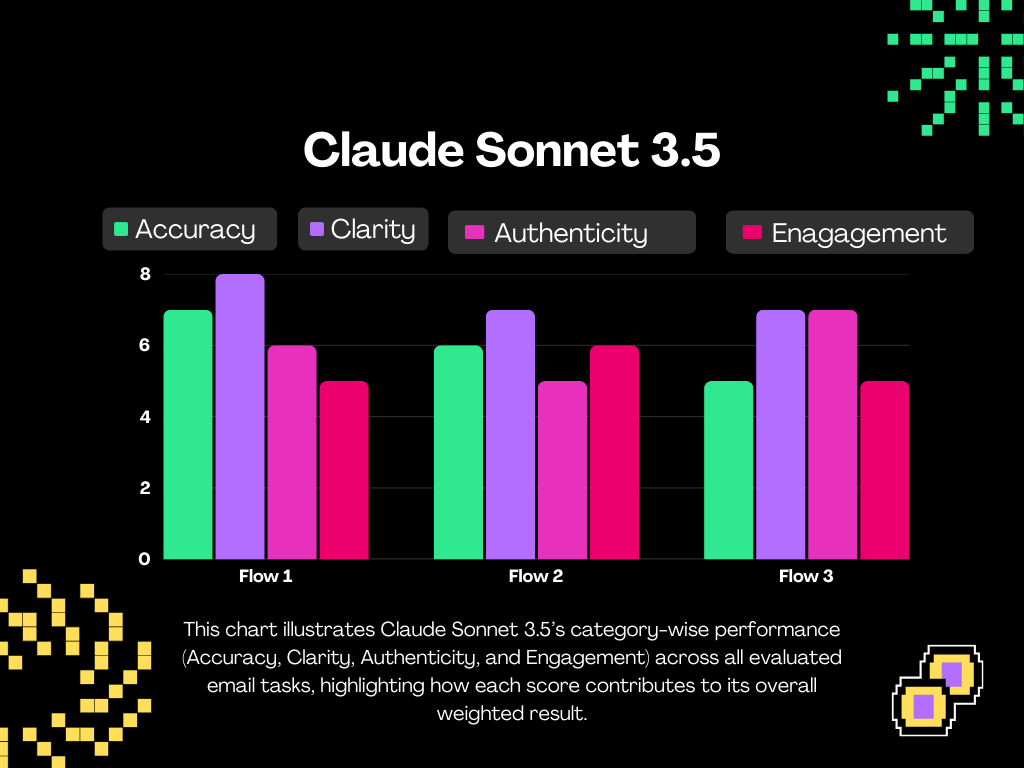
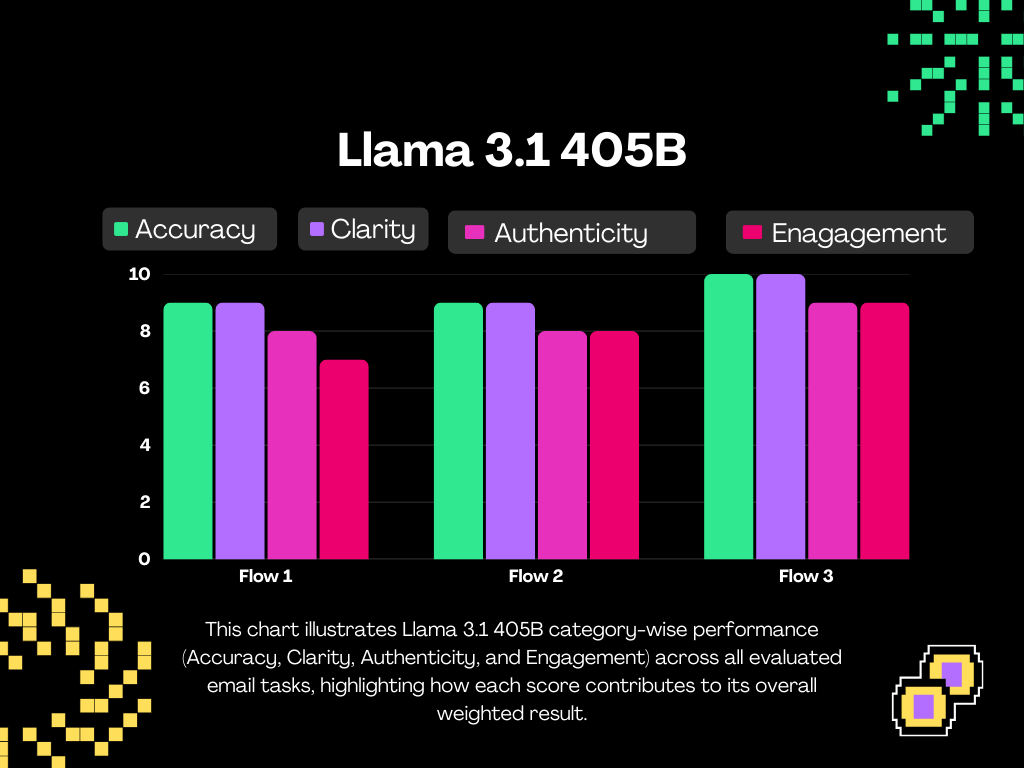
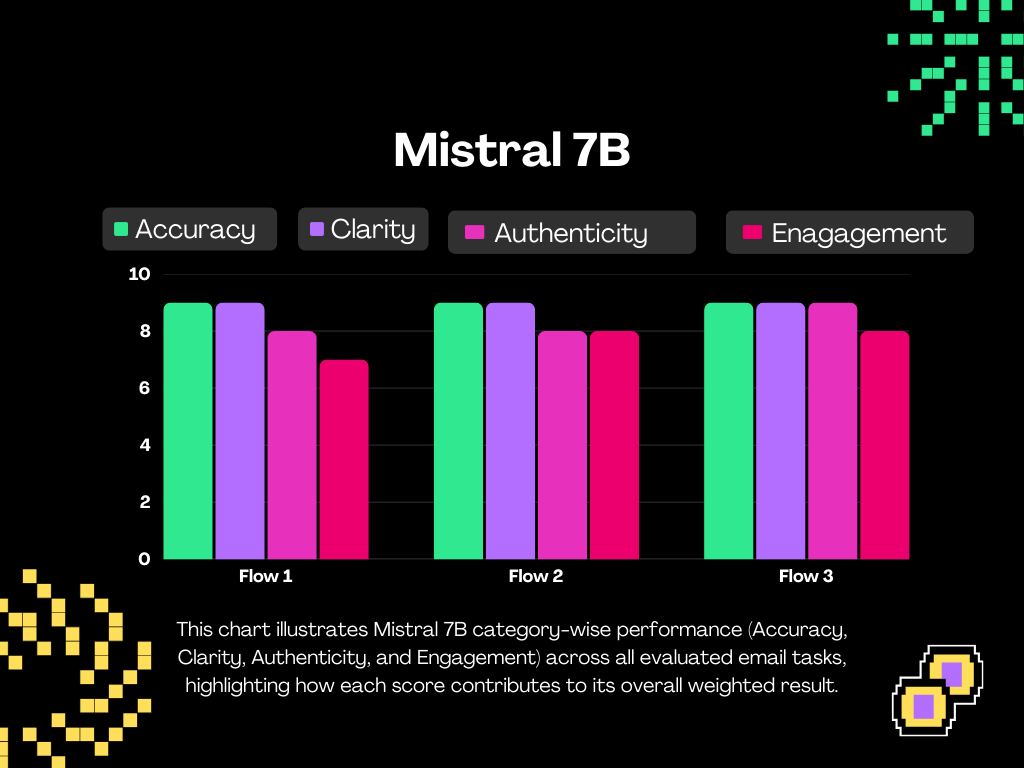
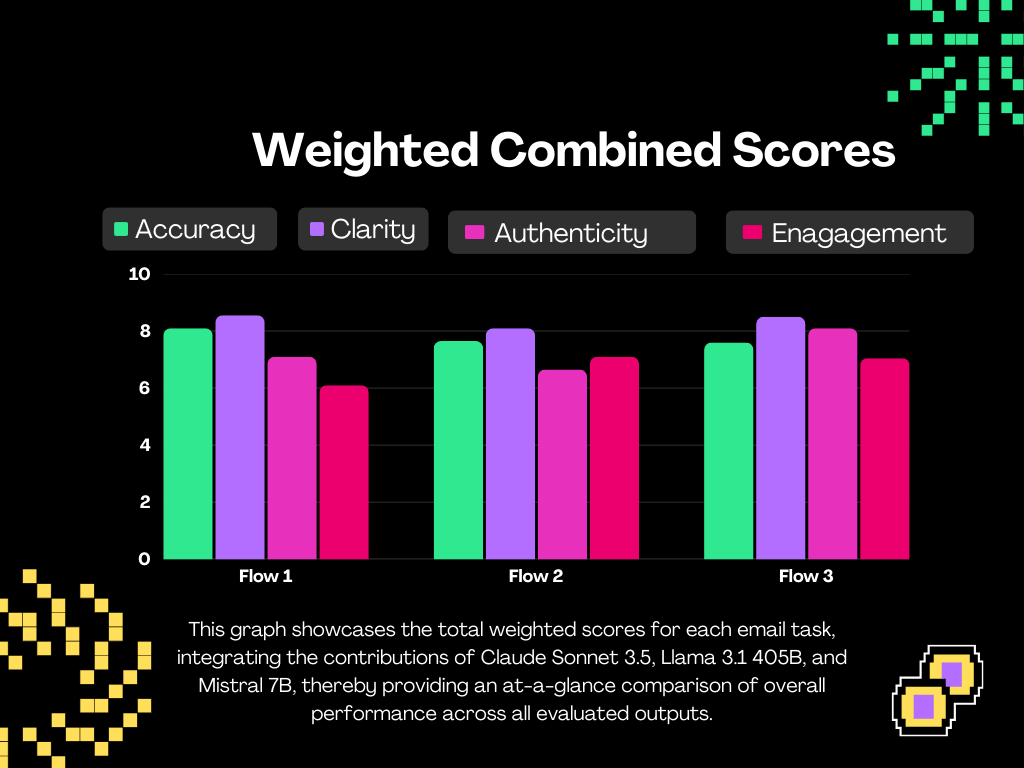
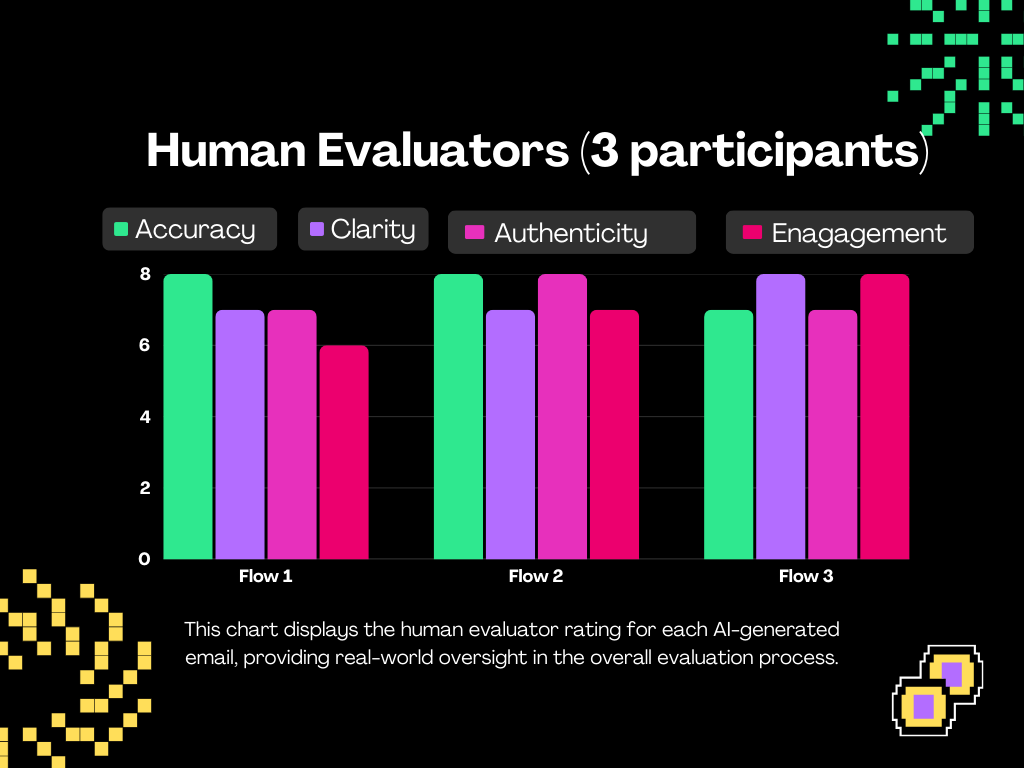
Key Considerations
Weight Allocation
The reason for attaching different weights to AI evaluators is to compensate for the models involved. In cases where different AI evaluators have different models, capabilities are different, with some models having larger parameters than others. Also, the sum of the weights must be equal to 10 to ensure homogeneity across all results. The exclusion of the human evaluator from the AI evaluator is to maintain the autonomy of the AI evaluators while also maintaining the standard of a human evaluation. A standard score is given to each to see how much the results stack up and the difference and also to know when to improve the system.
Bias Mitigation
The regular auditing of the data obtained from the AI evaluator prevents over-reliance on a single AI. The main role of the human evaluator is to monitor the system and correct systematic bias. A sharp decrease in the data obtained from a single AI can affect the score of the system, so proper monitoring is necessary to determine the reasons for each response.
Transparency and Explainability
The AI evaluators can give reasons for how they arrived at their given score. This shows what influences the AI decisions, especially in cases where a post was flagged or a loan was denied. This increases the transparency of the system and helps to flag biases early by the human evaluators.
Scalability and Efficiency
For larger projects, running a system like this will need high computational resources. So, optimising the workflow for faster decisions and managing the cost of the computational resources as the system scales is necessary. Also, the use of fine-tuned smaller models will help reduce the cost as compared to using conventional AI models for AI evaluations.
Challenges and Solutions
Bias Amplification
The use of homogeneous evaluators will increase the risk of reinforcing shared biases among the evaluators. The use of different training data and AI architecture is advised. Also, the use of weighted scores helps reduce the risk of biases.
Human-AI Collaboration
The training of human evaluators to understand the AI output to know what to look for when reviewing a response from the AI and also to reduce biases is important.
Potential Improvements
Dynamic Weighting
Adjusting the AI evaluator weight based on context, for example, changing the prioritising of benchmarks or AI models as the system progresses.
Consensus Mechanisms
The use of disagreement between AI evaluators and human evaluators to trigger deeper analysis. This helps increase the system of human-AI collaboration and reduces biases.
Continuous Learning
The main aim of the system is to enable it to learn from past evaluations and improve over time. The system can further be built to analyse inputs and prompts of the AI agents to further improve the results in real-time.
Conclusion
The multi-AI evaluation system provides a scalable, transparent, and efficient framework for assessing and improving AI agents. By combining AI and human evaluations, the system ensures high performance while mitigating biases and maintaining ethical standards. Continuous learning and dynamic adjustments will further enhance the system’s effectiveness over time.